Magic URL extractor is a cross-domain data extractor plugin, we are busy in developing a optimize plugin for various purpose. Till then use this plugin to extract cross domain commerce product details with URL (at this time plugin in beta version so only support top e-commerce sites in India).
The concept behind this script like as Seenit (Indian fashion social discussion like the app). It's also most awaiting Cross-Domain Access Plugin to access data without any API or XML permission.
Magic URL Data Extractor Work Phenomena
As we know well browser didn't support cross-domain request for accessing external data without JSONP, so our concept is simply based on such logic. When you proceed search button this script create a server request to load URL data in encrypted mode and while processing converts HTML data in XML/JSON format.
It's not easy to handle complete external DOM data without affecting your server load time so we create a virtual DOM and access data with a variable.
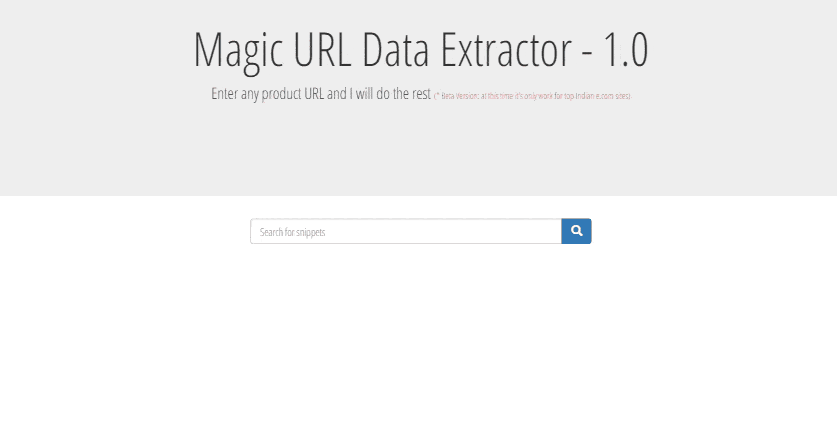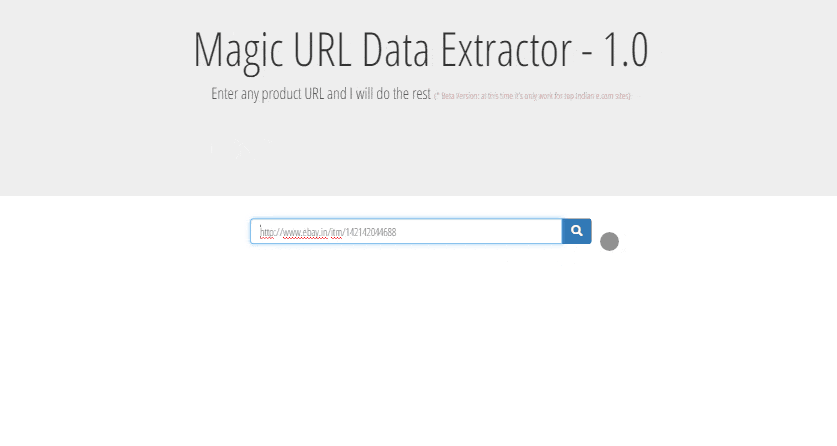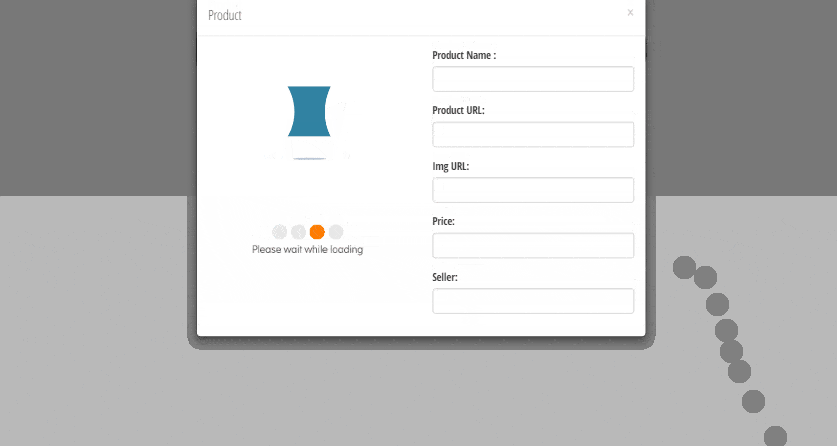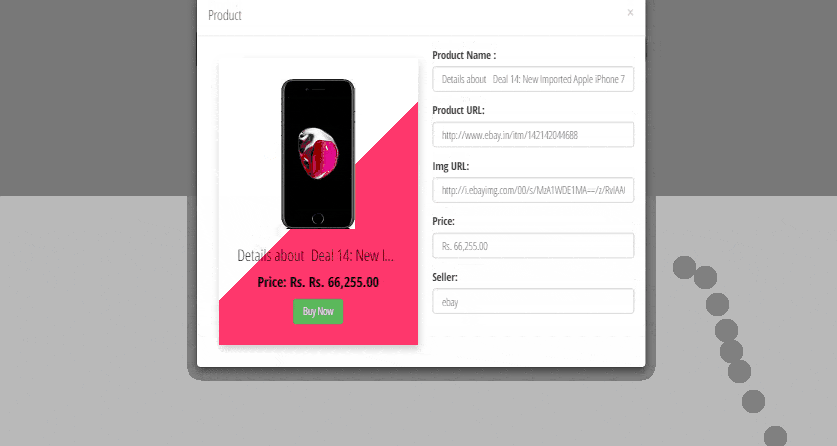
Our next step to filter data for Ajax, CSS, and Javascript request, after filtering all those things we process with converting in HTML format and store in a local container. We again process request to find exact data from the container and after getting all required result we display actual product only data.
URL --> Proxymapping --> CrossDomain request --> Request and save html data in Json--> Filter data to avoid concole erros and DOM optimization --> Proceess various data handling --> Show the result
Cross Domain Access Plugin, Handling DOM and Retrieving Data :
It's a deal to get cross-domain HTML data and convert into JSON format using YQL query, as below:
$.getJSON("http://query.yahooapis.com/v1/public/yql?"+
"q=select%20*%20from%20html%20where%20url%3D%22"+
encodeURIComponent(url)+
"%22&format=xml'&callback=?",
After retrieving the data surely we will filter unnecessary JS and CSS components.
data = data.replace(/<?\/body[^>]*>/g,''); data = data.replace(/[\r|\n]+/g,''); data = data.replace(/<--[\S\s]*?-->/g,''); data = data.replace(/<noscript[^>]*>[\S\s]*?<\/noscript>/g,''); data = data.replace(/<script[^>]*>[\S\s]*?<\/script>/g,''); data = data.replace(/<script.*\/>/,'');
We all know these things become laggy so and your DOM got heavy, yes exactly but for while. Script release Virtual DOM data as soon you got a final response.
GitHub Repo Demo Download Source Code



 About UsFind out working team
About UsFind out working team AdverisementBoost your business at
AdverisementBoost your business at Need Help?Just send us a
Need Help?Just send us a We are SocialTake us near to you,
We are SocialTake us near to you,